- 论文:http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.650.469&rep=rep1&type=pdf
信息抽取
根据主题词,在相应跳的范围内为候选答案构成主题图。
语法依存树(Dependency tree)通过提取问题词qword,问题焦点qfocus,问题主题词qtopic和问题中心动词qverb这四个问题特征,我们可以将该问题的依存树转化为问题图(Question Graph),如下图所示
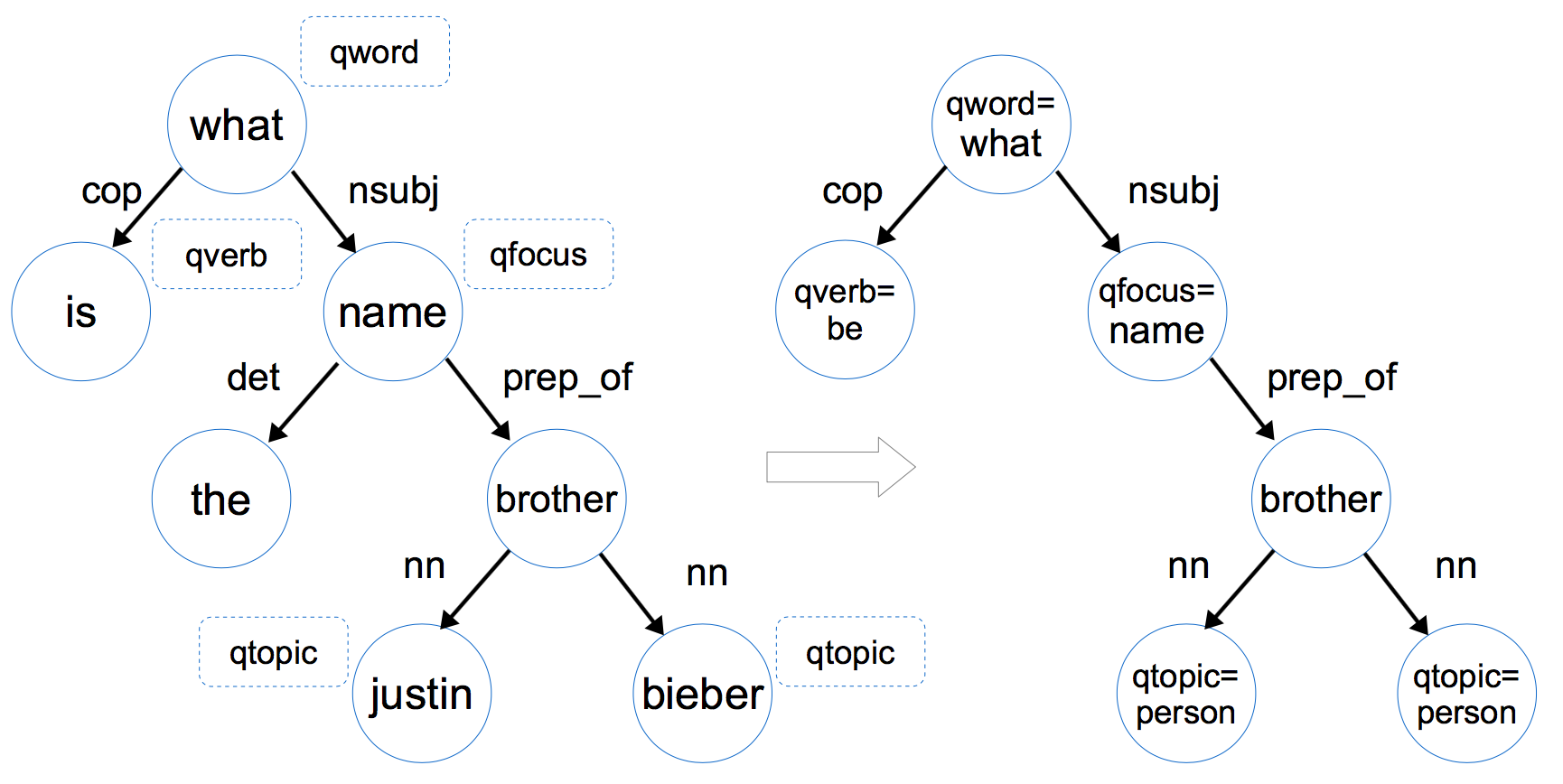
- 问题词(qword):例如 who, when, what, where, how, which, why, whom, whose
- 问题焦点(qfocus):这个词暗示了答案的类型,比如name/time/place,我们直接将问题词qword相关的那个名词抽取出来作为qfocus【可最后一步确定答案类型时确定】
- 主题词(qtopic):可通过命名实体识别。
- 中心动词(qverb):动词能够给我们提供很多和答案相关的信息,比如play,那么答案有可能是某种球类或者乐器。我们可以通过词性标注(Part-of-Speech,POS)确定qverb。
- 转换时还需去掉一些不重要的叶子节点,如限定词(determiner,如a/the/some/this/each等),介词(preposition)和标点符号(punctuation)
构建特征向量对候选答案进行分类
对于每个候选答案而言实际上是一个二分类问题,训练分类器,分类器的输入特征向量中的每一维对应一个问题-候选答案特征。每一个问题-候选答案特征由问题特征中的一个特征,和候选答案特征的一个特征,组合(combine)而成。
问题特征:从问题图中的每一条边e(s,t),抽取4种问题特征:s,t,s|t,和s|e|t。如对于边prep_of(qfocus=name,brother),我们可以抽取这样四个特征:qfocus=what,brother,qfocus=what|brother 和 qfocus=what|prep_of|brother。
候选答案特征:对于主题图中的每一个节点,我们都可以抽取出以下特征:该节点的所有关系(relation,记作rel),和该节点的所有属性(property,如type/gender/age)。
利用朴素贝叶斯计算了每一个关系R和整个问题Q的关联度,可表示为概率的形式\(P(R|Q)\)。
训练
- 使用Standford CoreNLP帮助对问题进行信息抽取。