句法分析:依存分析(Dependency Parsing)
1. 句法分析任务分类
根据句法结构的表现形式不同,最常见的句法分析任务可以分为以下三种:
- 句法结构分析(syntactic structure parsing),又称短语结构分析(phrase structure parsing),也叫成分句法分析(constituent syntactic parsing)。作用是识别出句子中的短语结构以及短语之间的层次句法关系。
- 依存关系分析,又称依存句法分析(dependency syntactic parsing),简称依存分析,作用是识别句子中词汇与词汇之间的相互依存关系。依存句法分析属于浅层句法分析。
- 深层文法句法分析,即利用深层文法,例如词汇化树邻接文法(Lexicalized Tree Adjoining Grammar, LTAG)、词汇功能文法(Lexical Functional Grammar, LFG)、组合范畴文法(Combinatory Categorial Grammar, CCG)等,对句子进行深层的句法以及语义分析。
2. 依存分析方法
PCFG、Lexical PCFG详见:https://blog.csdn.net/qq_28031525/article/details/79187080
用语言云分析依存句法和语义依存:语言云工具
生成句法分析树:基于概率上下文无关文法(PCFG)
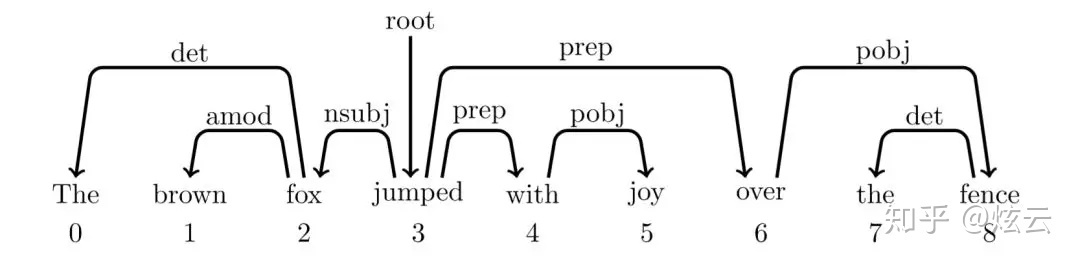
依存语句树:除了一个词,即根节点(这里为jumped)外,其他词都有词作为父亲节点,而该根节点(jumped)的父亲节点为root。
但是注意,依存句法树是不允许弧之间有交叉或者回路!
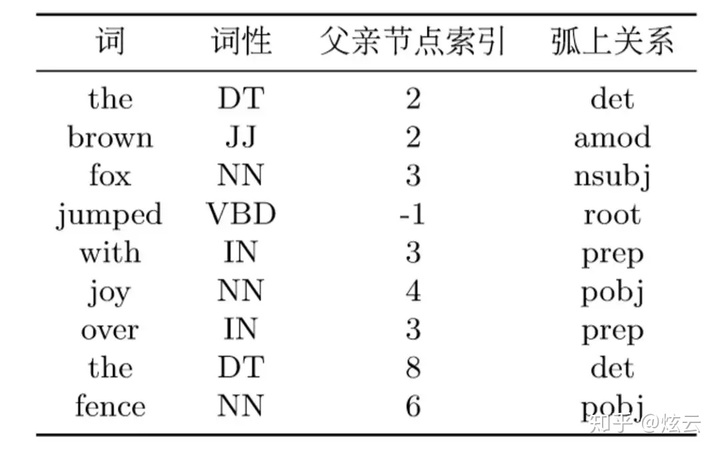
文本表示格式为conll格式:
传统的基于转移的依存分析(Transition-based Parsing)
框架由状态和动作两部分构成,其中状态用来记录不完整的预测结果,动作则用来控制状态之间的转移。
构造一个三元组,分别是
- Stack:最开始只存放一个Root节点;
- Buffer:则装有我们需要解析的一个句子;
- Set:中则保存我们分析出来的依赖关系, 最开始是空的。
用在生成依存句法树上,则具体表示为从空状态开始,通过动作转移到下一个状态,一步一步生成依存句法树,最后的状态保存了一个完整的依存树。依存分析就是用来预测词与词之间的关系,现在转为预测动作序列。在基于转移的框架中,我们定义了4种动作(栈顶的元素越小表示离栈顶越近):
移进(shift):将buffer中的第一个词移出并放到stack上。
左规约(arc_left_I):栈顶两个元素规约,左边节点下沉成为孩子节点,为弧上关系
右规约(arc_right_I):栈顶两个元素规约,右边节点下沉成为孩子节点,为弧上关系
根出栈(pop_root):根节点出栈,分析完毕
其中下沉的意思:
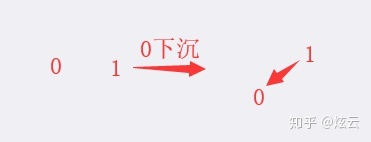
0下沉,0是1的孩子
具体例子理解:
以上面依存树为例:
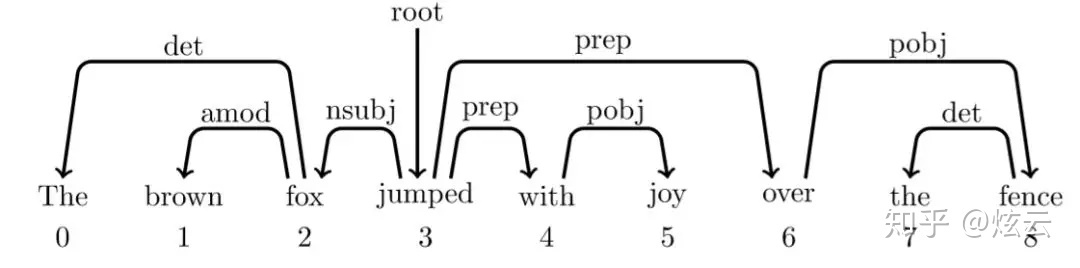
一整套分析的动作序列为:
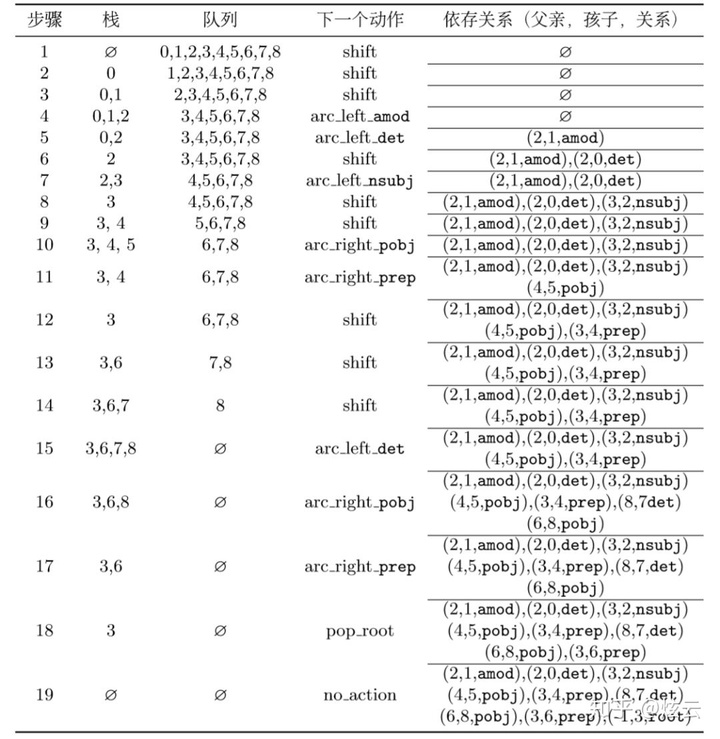
初始状态

栈为空,队列为整个文本的数字序列。这个时候只能进行移进shift操作:
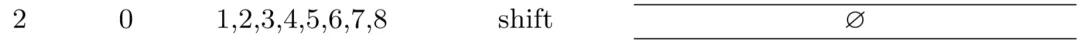
因为左边栈只有一个元素0,还是只能进行移进shift操作:
这个时候栈中有2个元素,我们此时看依存树
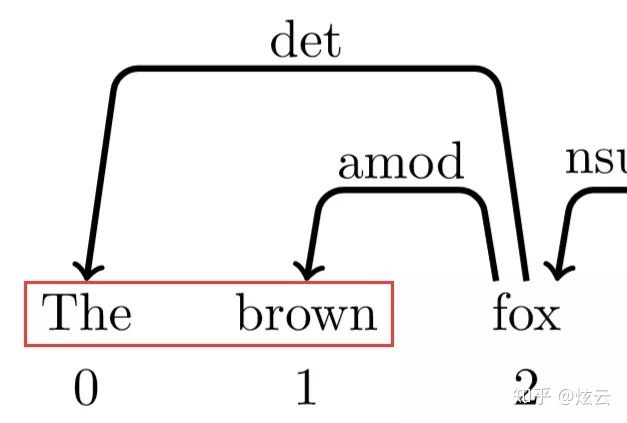0、1之间并没有弧,不能进行规约,所以还是只能shift:
此时看栈顶两元素,发现依存树中1、2之间有依存关系
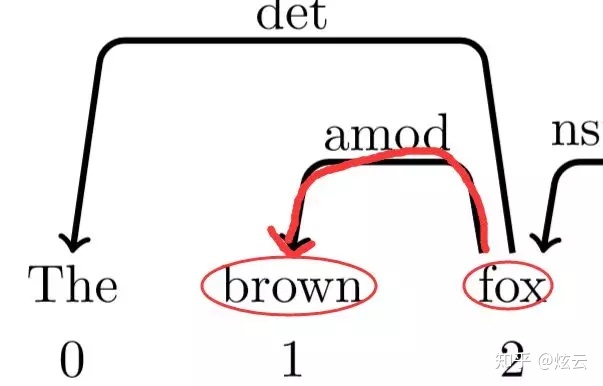而且1为2的孩子,所以此时的动作为左规约arc_left,1下沉,为2的孩子(此时实际操作为1被踢出栈,栈里剩为0、2,踢出是因为最后能根据动作序列还原整个依存树,当然也为了接下来的操作方便),此时标签为amod:
此时栈里为0、2,再次查看依存树
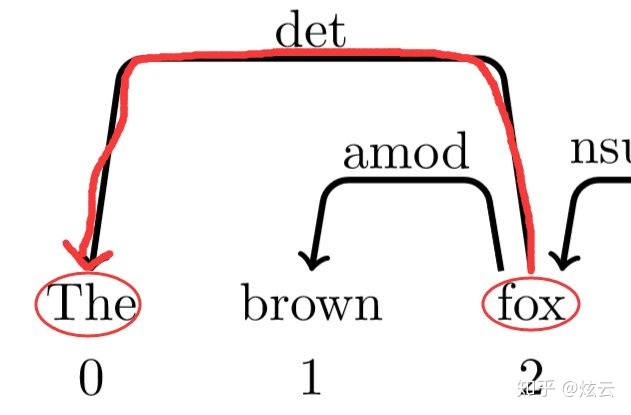发现0、2之间有依存关系,其中0为2的孩子,所以此时操作为左规约,此时标签为det
...
中间略过一些步骤,因为都是同理,这次说下第9步:
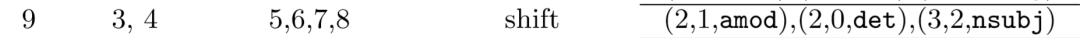
此时栈中为3、4,查看依存树
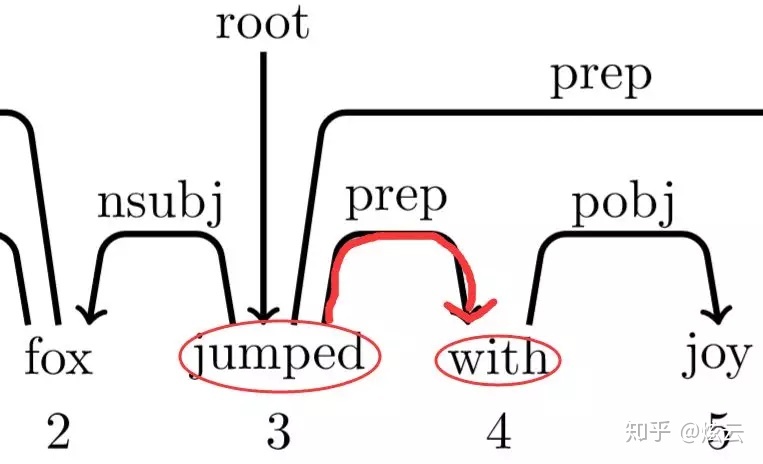
按照正常操作,此时应该arc_right右规约,但是如果真的4就下沉,就没了。而一会5要入栈,再查看依存树发现4是自己的父节点,天呐,5的父节点没了,其他词都有父节点,就5没有,还有比这个更惨的吗?这就没发再进行操作了!所以,还有一个潜规则如果操作为栈顶元素要进行arc_right时,不执行该操作,而选择shift。
而你可能会问arc_left会有这样的问题吗?不会啦,比如3、4进行arc_left操作,3下沉,如果右边的队列中有父亲节点是3,那么就表示该依存树有交叉或者回路!这种是不可能发生的,因为依存树不允许有交叉或者回路!
最后说下,pop_root根弹出操作,只能发生在最后

右下角的数据为词与词之间的关系,这个就是根据动作序列生成的依存关系(父亲,孩子,关系),根据该关系,就能还原成原来的依存树。



神经网络模型
- 利用神经网络进行特征提取,分为两部分:
- 编码器:用来负责计算词的隐层表示
- 解码器:用来解码计算当前状态的所有动作得分
编码器
用Bi-LSTM来编码一个句子\((e_1,e_2,...,e_n)\)计算对应的隐层表示。公式为: \[ \{h_1,...,h_n\}=Bi-LSTM(\{e_1\oplus p_1,...,e_n\oplus p_n\}) \]
其中:\(e\)为词向量,\(p\)为词性向量,\(\oplus\)是向量拼接
解码器
解码端就需要对每一个状态打出所有动作的得分。根据经验,认为栈顶三元素和队列首元素为动作预测关键特征,于是将栈顶三元素(下标越小离栈顶越近)和队列首元素进行拼接。然后用线性变换计算每一个动作的分数: \[ o=Linear(h_{s0}\oplus h_{s1}\oplus h_{s2}\oplus h_{q0}) \]
对每一个动作的分数进行Softmax概率化,然后输入到交叉熵中,作为目标函数。然后再用Adam来进行更新模型参数,最小化目标函数
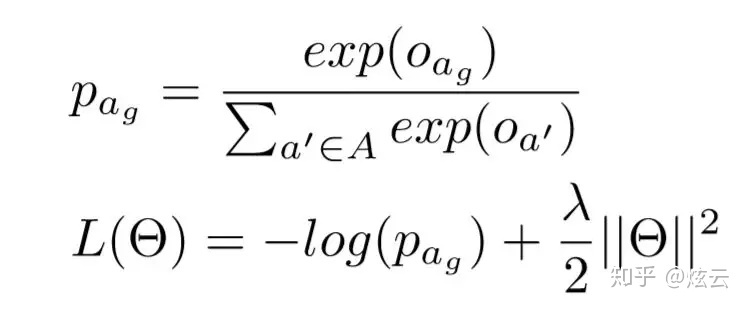
其中\(p_{a_g}\)为动作序列概率,\(\Theta\)为模型参数