- 论文原文:https://www.aclweb.org/anthology/2020.acl-main.91.pdf
1. Introduction
- 目前主要在研究两种复杂性问题:
- 带约束的单一关系问题(Single-relation questions with constraints)
- 具有多跳关系的问题(Questions with multiple hops of relations)
- 减少需考虑的多跳关系路径的数量,本文采用beam search,即consider only the best matching relation instead of all relations when extending a relation path.
- 本文同时处理复杂KBQA的约束和多跳关系。
- 在查询图的生成过程中,允许更长的关系路径。
- 不再是关系路径构建完成之后再添加约束,而是同时合并约束和扩展关系路径,可以减少搜索空间。
2. Method
2.1 Preliminaries
现有的查询图生成方法【本文largely inspired by】
【Semantic parsing via staged query graph generation: Question answering with knowledge base, 2015
Constraint-based question an- swering with knowledge graph, 2016
Knowledge base question answering via en- coding of complex query graphs, 2018】
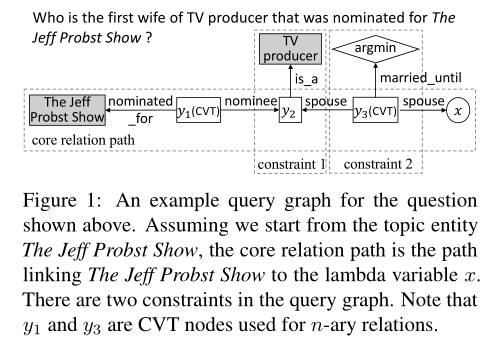
一个查询图(query graph)有四种结点:
- grounded entity(带阴影的矩形):知识库中已经存在的实体
- existential variable(无阴影的矩形):不是一个grounded entity
- lambda variable(圆形):不是一个grounded entity,但是代表了答案
- aggregation function(菱形):聚合函数
查询图的边来自知识图中的关系,一个查询图应该只有一个lambda变量表示答案,不止一个grounded entity、没有或者多个existential变量和聚合函数。
查询图生成过程(Yih et al., 2015; Bao et al., 2016):
Starting from a grounded entity found in the question (referred to as a topic entity), identify a core relation path linking the topic entity to a lambda variable. Existing work considers core relation paths containing a single relation(Yih et al., 2015; Bao et al., 2016; Luo et al., 2018).
From a core relation path identified in Step 1, attach one or more constraints found in the question. A constraint consists of either a grounded entity or an aggregation function together with a relation.
With all the candidate query graphs generated from Step 1 and Step 2, rank them by measuring their similarities with the question. This is typically done through a neural network model such as a CNN . (Yih et al., 2015; Bao et al., 2016).
Execute the top-ranked query graph against the KB to obtain the answer entities.
2.2 Motivation
- 看起来更像是两个模型的组合:上述模型不利于解决多跳问题;最新研究出的多跳模型(beam search,在生成t+1跳关系路径之前只保留前K个t跳关系路径【(Chen et al., 2019; Lan et al., 2019b)】)但忽略了在生成过程中的约束。
- 不再是关系路径构建完成之后再添加约束,而是同时合并约束和扩展关系路径。
- This more flexible way of generating query graphs, coupled with a beam search mechanism and a semantic matching model to guide pruning, explores a much smaller search space while still maintaining a high chance of finding the correct query graph.
2.3 Query Graph Generation
利用波束搜索来迭代生成候选查询图。假设第\(t\)次迭代产生K个查询图的集合,在\(t+1\)次迭代中,作者使用了extend、connect、aggregate三个行为之一来为当前的查询图添加一条边或一个节点。在每个时间步获得查询图之后,用评分函数来对所有查询图进行排序,并找出 top-k。如此持续迭代,直到某一迭代的评分不高于它前一迭代的评分。
如下图:
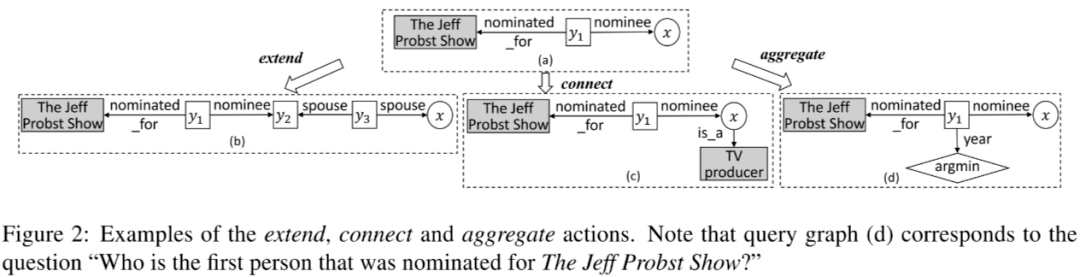
2.3.1 extend
- 扩展动作将核心关系路径扩展了 R 中的一个关系。如果当前查询图仅包含主题实体 e,则扩展动作将在 KB 中找到链接到 e 的关系 r,并将路径增长到 r。它还使 r 的另一端成为 lambda 变量 x。如果当前查询图具有 lambda 变量 x,则扩展操作会将 x 更改为存在变量 y,通过对 KB 执行当前查询图来查找 KB 中 y 的所有绑定,找到链接到这些实体之一的关系 r ,最后将 r 附加到 y。r 的另一端成为新的 lambda 变量 x。
2.3.2 connect
- 除了当前核心关系路径开始处的主题实体之外,问题中通常还会找到其他实体。 连接操作将这样的实体 e 链接到 lambda 变量 x 或连接到 x 的存在变量(即 CVT 节点)。要确定使用哪个关系 r 链接 e 和 x,我们可以再次找到 x 的所有绑定,通过执行当前查询图,然后找到这些实体之一与 e 之间存在的关系。
2.3.3 aggregate
- 作者使用一组预定义的关键字从问题中检测聚合函数。聚合操作会将检测到的聚合函数作为新节点附加到 lambda 变量 x 或连接到作为 CVT 节点的 x 的存在变量。
2.3.4 总结
- 该方法的新颖之处在于,可以在连接和聚合操作之后应用扩展操作,而以前的方法是不允许的。扩展和连接操作可以理解为对多跳推理的实现,而聚合操作可理解为对问题约束的实现。
2.4. Query Graph Ranking
- 在第 t 次迭代的末尾,算法对候选查询图进行排序,每个图获得 7 维的特征向量,并将这些向量馈送到一个全连接层。
- 向量的第一个维度来自基于 BERT 的语义匹配模型。具体来说,算法通过遵循构造查询图 g 所采取的动作序列并将每个步骤所涉及的实体和关系的文本描述顺序添加到序列中,将 g 转换为标记序列。存在变量和 lambda 变量将被忽略。
- 向量的其他 6 个维度如下:第一个维度是查询图中所有已链接实体的累积实体链接得分。第二个是查询图中出现的链接实体的数量。第三到第五个分别是查询图中实体类型的数量,时间表达式和最高级的数量。最后一个特征是查询图的答案实体的数量。
引用
Semantic parsing via staged query graph generation: Question answering with knowledge base, 2015
Constraint-based question an- swering with knowledge graph, 2016
Knowledge base question answering via encoding of complex query graphs, 2018
Uhop: An unrestricted-hop relation extraction framework for knowledge-based question answering, 2019
Multi-hop knowledge base question answering with an iterative sequence matching model, 2019b