论文:https://www.aclweb.org/anthology/2020.nli-1.1.pdf
Abstract
- 在这项工作中,我们着眼于回答复杂的问题,这些问题往往需要结合来自多个来源的信息。提出了一种新颖的知识库问答系统MULTIQUE,它可以通过一系列针对特定知识库的简单查询将复杂问题映射为复杂查询模式。它使用基于神经网络的模型发现简单查询,该模型能够对抽取知识库中的文本关系和精选知识库中的本体关系进行集体推理。
1. Introduction
利用curated KB和extracted KB一起回答,二者互为补充
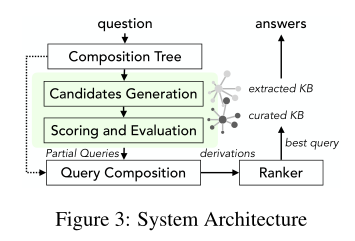
MULTIQUE构建查询路径来回答来自简单查询的复杂问题,每个查询都针对特定的知识库。
在语义解析的基础上,遵循enumerate-encode-compare方法。首先收集候选查询并编码为语义向量,然后与问题向量进行比较。然后在知识库上执行具有最高语义相似度的候选。
提出了两个关键修改:为了能够对知识库中的本体[curated KB]和文本关系[extracted KB]进行集体推理,首先对不同关系进行对齐,并学习了统一的语义表示。其次,由于缺乏完整注解的查询来训练模型,我们使用问题答案形式的隐式监督信号来学习。
2. Task and Overview
Complex Question:
- 问题Q对应的一个查询(query)G有不止一个关系,但只有一个查询焦点(query focus)。G是一个部分查询(partial queries)\(G=(G_1,G_2,...,G_O)\)通过不同条件连接起来的序列。
- 一个部分查询包含四个基本要素
- a seed entity \(s^r\) is the root of the query
- a variable node \(o^v\) corresponds to an answer to the query
- a main relation path \((s^r,p,o^v)\) is the path that links \(s^r\) to \(o^v\) by one or two edges from either \(R^o\) or \(R^t\)(两种知识库中的关系)
- constraints take the form of an entity linked to the main relation by a relation \(c\)
- 一个合成树(composition tree)\(C\)描述如何在给定部分查询的情况下构造和评估查询\(G\),包含两个函数:
- \(simQA\) 是用于查找简单查询的模型,它枚举简单查询的候选项,对其进行编码,并与问题表示进行比较,然后评估出最佳候选项
- \(join\)描述了如何连接两个部分查询,即它们是否共享查询焦点或另一个变量节点
方法总览:
给定一个复杂的输入问题
- 首先计算一颗合成树,该树描述如何将推理分解为简单的部分查询
- 从curated和extracted KBs中为每个部分查询收集候选查询
- 对于每个候选,使用一个基于神经网络模型来衡量其与问题的语义相似性,该模型可对不同形式的关系进行推理
- 联接不同的部分查询找到问题的复杂查询
- 将派生出的几个完整的查询根据它们部分查询的语义相似分数(semantic similarity of their partial queries)、查询结构(query structure)和实体链接分数(entity linking scores)对其进行排序,在多个KB上寻找最佳推导。下图为MULTIQUE的体系结构:
3. Partial Query Candidate Generation
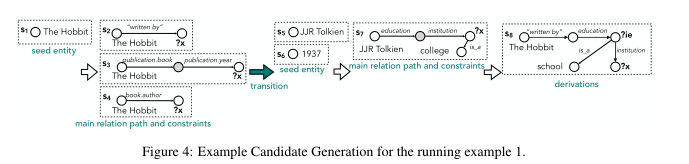
3.1 Identify seed entity
- 部分查询的seed \(s^r\) 是问题中的链接实体或先前评估的部分查询的答案。
3.2 Identify main relation path
- 给定一个种子实体,考虑所有1跳和2跳路径\(p\),包括ontological and textual relations,路径的另一端是变量结点\(o^v\)。
3.3 Identify constraints
- 上一步确认的那些要给个实体和类型约束(entity and type constraints)。在例子中,我们考虑利用约束关系is_a来查找变量结点\(o^v\)。我们还考虑通过单个关系连接到路径上的实体。我们还考虑约束的子集,以支持具有多个约束的查询。
3.4 Transition to next partial query
- 一旦收集到部分查询\(G_i\)的候选,我们就参考合成树来确定下一部分查询\(G_{i+1}\)的开始状态。
- 如果下一个操作是simQA,我们使用语义匹配模型来计算\(G_i\)候选的语义相似度,并评估K个最好的候选。否则,继续生成\(G_i\)中不重叠的实体链接候选。
4. Semantic Matching
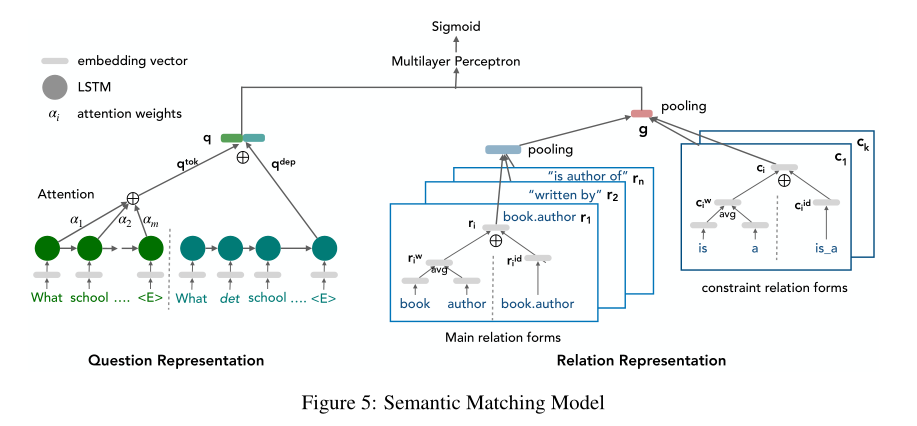
4.1 Model Architecture
4.1.1 Encoding question
- 使用令牌序列(token sequence)和依存结构(dependency structure)。
- \(<w_1,w_2,...,w_n>\)是\(Q\)中的令牌,其中,seed(constraint)已经被替换为\(w_E,w_C\)
- 利用embedding矩阵\(E_w\)将token转换成向量\(<q_1^w,q_2^w,...,q_n^w>\)
- 再利用LSTM将序列编码为一个潜在向量\(q^w\)
- 类似地,将依存数编码为一个潜在向量\(q^{dep}\)
4.1.2 Encoding main relation path
主关系路径可能是来自\(K_o\)的textual relation,也可能来自\(K_c\)的ontological relation,为在同一空间推断,需进行关系对齐
在关系对齐的情况下,对 对齐中的每个关系形式编码为潜在向量\(r_i\)。然后对不同关系的潜在向量进行最大合并,以获得不同关系形式上的统一语义表示。
为了将每种关系形式编码成向量\(r_i\),考虑符号序列和id序列(Luo et al., 2018)。
For instance, the id sequence of the relation in Fig. 5 is {book_author}, while its token sequence is {‘book’, author’}.
- 符号序列:将token编码成向量利用embedding矩阵,最后将average embedding记作token层的表示\(r^w\)。
- id序列:直接利用embedding矩阵\(E_r\)计算id层的表示\(r_i^{id}\)
一条路径的向量最终表示为\(r_i=[r_i^w;r_i^{id}]\)
4.1.3 Encoding constraints
- 同样的方法利用token级的表示\(c_i^w\)和id级的表示\(c_i^{id}\)编码约束关系\(c_i\)。
- 给定关系路径和约束路径的向量表示,我们通过应用max pooling来获得查询语句的组合语义表示(compositional semantic representation)\(g\)。
4.1.4 Attention mechanism
利用查询向量\(g\)学习问句中的emphasize parts。
给定token层表示中的各隐藏层\(h_t,\ t\in \{1,2,...,n\}\),定义上下文向量[context vector]\(c\)作为所有隐藏状态的加权和: \[ c=\sum_{t=1}^n\alpha_th_t \] \(\alpha\)是注意力权重,计算公式为: \[ \alpha=softmax(Wtanh(W_qq^w+W_gg)) \]
其中\(W,W_g,W_q\)是网络的参数矩阵。注意力权重表示给定部分查询,模型对各个token的关注度。
4.1.5 Objective function
将上下文向量\(c\)、问题依存向量\(q^{dep}\)和查询向量\(g\)连接起来,一起送到多层感知机(MLP)中。输出为一个标量,表示语义相似度分数\(S_{sem}(q,G_i)\)。使用交叉熵损失函数来训练模型。 \[ loss=ylog(S_{sem})+(1-y)log(1-S_{sem}) \] \(y\in \{0,1\}\)表示\(G_i\)是否正确。
训练模型需要对等关系表单的对齐和(question, partial query)对。我们描述如何在给定QA对的情况下生成它们。
4.2 Relation Alignment
- 首先学习textual嵌入然后对其进行聚类以获得规范化(canonicalized)关系蔟(Vashishth et al., 2018)。例如,一个聚类可以包含"is author of"和"authored"。
- 使用规范化的文本关系(canonicalized textual relations)来推导出与本体论关系(ontological relations)的对齐。
- 基于一对 本体关系 和 规范化文本关系 的 支持实体对\((s,o)\) 来实现这种对齐。
- 以我们的示例问题为例,关系"is author of"和book.author一定比关系"is author of"和education.institution有更多关联实体。
- 该对齐基于支持阀值,即一对关系的最小数量的支持实体对,本文中设置为5.
4.3 Implicit Supervision
候选查询的质量可以通过计算其对标签答案的\(F_1\)分数间接获得(Peng et al., 2017a)。但是对于复杂问题,候选查询的答案可能与标签答案几乎没有重叠。
因此采用另一种评分策略,将部分查询的质量估计为其所有完整查询派生的最佳\(F_1\)分数。计算部分查询的分数\(V(G_i^{(k)})\)为: \[ V(G_i^{(k)})=\max_{i\leq t \leq n-1}F_1(D_{t+1}^{k}) \] 其中\(D_t\)表示级别\(t\)的派生,\(n\)表示部分查询的数量。
这种隐含监督可能收到虚假推导的影响,恰好评估出了正确答案,却没有捕捉到问题的语义含义,所以还需要考虑额外的先验来促进训练数据中的真阳性和假阴性的示例。
我们使用\(L(Q,G_i^{(k)})\)作为问题\(Q\)中提到\(G_i^{(k)}\)的关系中的词数之比。也使用\(C(Q,G_i^{(k)})\)