- 论文地址:https://www.aclweb.org/anthology/N19-1270.pdf
Abstract
- 在给定有限的计算资源(只有一个预先训练的模型和固定数量的训练实例)的情况下,我们提出了三个通用策略——即时机器提取阅读理解(MRC):(1)考虑输入序列的原始顺序和反向顺序的前后阅读(BACK AND FORTH READING, BF),(2)高亮显示(HIGHLIGHTING, HL),这将可训练的嵌入添加到与问题和候选答案相关的标记的文本嵌入中,以及(3)自我评估(SELF-ASSESSMENT, SA),这将直接从文本中以无监督的方式生成练习问题和候选答案。
1. Introduction
本文主要关注于非提取型MRC,其中相当大比例的候选答案不限于参考文档或语料库的文本spans。与提取型MRC任务(第2.1节)相比,非提取型MRC(第2.2节)需要不同的阅读技能,因此,机器读者在这些任务上的表现更准确地表明了机器读者在现实环境(如考试)中的理解能力(赖等人,2017年)。
在微调时提高机器阅读理解能力,而不是通过昂贵的预训练。提出了三个相应的领域独立地策略,以提高基于目前现有的pre-trained transformer模型的MRC(Sec 3.1)。
- BACK AND FORTH READING(“我在文本中前前后后寻找其中的想法之间的关系。”):考虑输入序列的原始顺序和反向顺序(第3.2节)
- HIGHLIGHTING(“我突出显示文本中的信息,以帮助我记住它。”)在与问题和候选答案相关的标记的文本嵌入中添加一个可训练的嵌入(第3.3节)
- 自我评估(“我问自己想在文本中回答的问题,然后检查我对文本的猜测是对还是错。”):从现有参考文件中生成练习问题及其相关的基于范围的候选答案(第3.4节)
2. Task Introduction
- 根据预期的答案类型(其实是根据目前现有的数据集类型),将机器阅读理解分为两大类:提取型(extractive)(Sec 2.1)和非提取型(non-extractive)(Sec 2.2)
2.1 提取型MRC
- 给定一个参考文档和一个问题,期望的答案是文档的一小段。
- 另一种:在例如SearchQA和NarrativeQA等数据集上的答案则是基于给定文档的由人设置的自由形式的文本。然而由于注释者倾向于直接复制spans作为答案,所以大多数答案仍然是提取的。
2.2 非提取型MRC
主要讨论多选择MRC数据集,其中答案选项不限于提取的文本范围。给定一个问题和一个参考文档/语料库,提供多个答案选项,其中至少有一个是正确的。
与抽取式MRC任务中的问题相比,除了表面匹配之外,还有各种类型的复杂问题,如数学应用题、摘要、逻辑推理和情感分析,需要高级阅读技能和先验世界知识。此外,在大多数情况下,我们可以采用准确性等客观的评估标准来评估系统性能(克拉克等人,2016;Lai等人,2017)。
3. Approach
3.1 Framework Overview
遵循有区别地微调生成预训练transformer的框架(GPT)。它采用预先训练的多层transformer将语言模型转换为标记数据集\(C\),其中每一个实例由一系列输入标记\(x^1,...,x^n\)及标签\(y\),最大化: \[ \sum_{x,y}logP(y|x^1,...,x^n)+\lambda \cdot L(C) \] \(L\): 语言的似然函数
\(\lambda\): 语言模型的权重
\(P(y|x^1,...,x^n)\): 通过语言模型的最后transformer模块激活上的线性分类层得到的。
对于多选择MRC,\(x_1,...x_n\)来自开始标记、参考文档、问题、分隔符标记、答案选项和结束标记的连接
\(y\)表示答案选项的正确性。
下图为整体框架
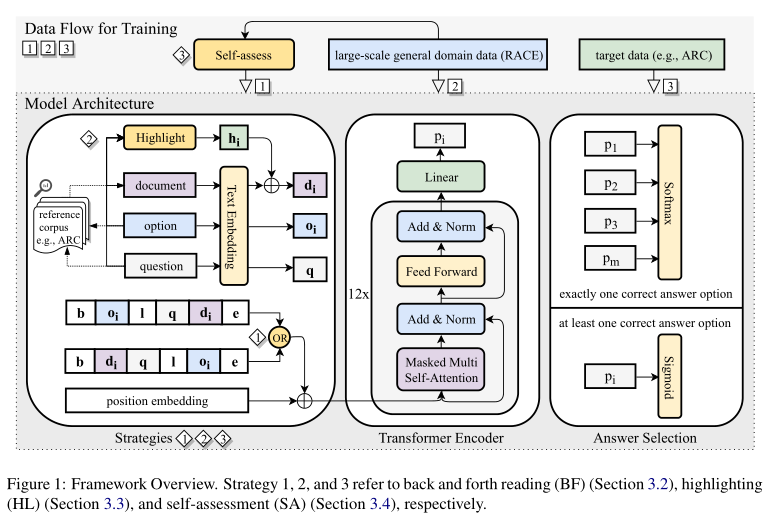
3.2 Back and Forth Reading(BF)
- 将GPT原始输入序列表示为\([dq\ \$\ o]\),其中\([\ ,\$\ \)和\(]\ \)分别表示开始标记(start token),定界标记(delimiter token)和结束标记(end token)。
- 考虑原始序列和反向序列\([o\ \$\ qd]\)。\(d,q,o\)中的token依旧保留。分别对两个分别使用\([dq\ \$\ o]\)和\([o\ \$\ qd]\)作为输入序列的GPT进行微调,然后将两个模型合在一起。
- 同时还考虑了其他类似的输入序列对,例如\([qd\ \$\ o]\)和\([o\ \$\ dq]\)。【Sec. 4.3】
3.3 Highlighting(HL)
文档的文本嵌入独立于其相关的问题和候选答案。旨在使文档编码了解相关的问答选项对\((q,o_i)\)。专注于问题和答案选项中的内容词,我们通过其词性(POS)标签(例如:名词、动词、形容词、副词、数字、或外来词)来分辨内容词。
\(T\):POS标签集
\(d\):文档\(d\)的文本嵌入顺序
\(d^j\):表示\(d\)中第\(j\)个token【对应文档\(d\)】,表示\(d\)中的第\(j\)个文本embedding【对应embedding】
给定文档\(d\)和一个问题答案对\((q,o_i)\),我们将文档\(d\)中第\(j\)个token对应的highlight embedding\(h_i^j\)定义为

高亮嵌入\(h_i=h_i^1,h_i^2,...,h_i^n\)的长度与\(d\)相同。当对文档编码时,将\(d\)替换成\(d_i=d+h_i\)。更具体地说,我们在微调期间使用\(b,d_i,q,l,o_i\)和\(e\)的concatenation作为GPT的新输入【Sec. 3.1】,其中\(b,l\)和\(e\)分别表示开始token、分割符号token和结束符号token的embedding,\(q\)和\(o_i\)分别表示\(q\)和\(o_i\)的文本embedding序列。
3.4. Self-Assessment(SA)
在自我评估阅读策略的启发下开发了一种微调方法。我们提出了一种简单的方法来生成问题及其关联的多个基于span的答案选项,这些选项涵盖了参考文档中多个句子的内容。目标是使得到的微调模型更了解输入结构,并根据回答给定问题可能需要的跨多个句子集成信息。
基于结束任务(即本文中的RACE)的每个文档随机生成不超过\(n_q\)个问题和相关的答案选项,步骤描述如下:
- 输入:来自结束任务的参考文档
- 输出:与参考文档相关联的一个问题和四个答案选项
- 从文档中随机选择不超过\(n_s\)个句子,并将这些句子连接在一起。
- 从连接的句子中随机选择不超过\(n_c\)个不重复的span。每个span在单个句子中随机包含不超过\(n_t\)个token。我们将选定的span连接起来,以形成正确的答案选项。我们从连接的句子中删除选定的span,并使用剩余的文本作为问题。
- 通过将正确答案选项中的span随机替换为从文档中随机选出的span,生成三个干扰项(错误选项)
- \(n_q,n_s,n_c,n_t\)都是用于控制问题的数量和难度级别。