- 论文:http://nlp.csai.tsinghua.edu.cn/documents/57/Grounded_Conversation_Generation_as_Guided_Traverses_in_Commonsense_Knowledge_Graphs.pdf
Abstract
- 会话生成模型ConceptFlow通过将会话建立在概念空间(concept space)的基础上,将潜在的会话流表示为沿着常识关系(commonsense relations)在概念空间中的遍历。遍历是由概念图中的图注意力引导,在概念空间中向更有意义的方向移动,以产生更多的语义和信息响应。
1. Introduction
之前的生成模型可能会退化为枯燥和重复的内容,会导致离题和无用的响应。人类的对话是围绕着一些相关的概念聊天,并将注意力从一个概念转移到另一个概念
解决办法:基于外部知识,如开放领域知识图、常识知识库或背景文件。最近的研究利用了这些外部知识,将它们用于基础会话,将它们整合为额外的表示,然后根据文本和基础语义生成反应。将外部知识整合为额外的语义表示和会话模型的额外输入。
对人类会话中的概念转换进行建模,本文提出了ConceprFlow(ConceptFlow generation with Concept Flow),利用常识知识图对显示概念空间中的会话流进行建模
概念图中的遍历是由图注意力机制来引导的,图注意力机制来源于图神经网络,用来关注更合适的概念,使得ConceptFlow学习可以沿着更有意义的关系对会话发展建模。将常识知识建模为概念流,既是通过将当前对话焦点分散到其他概念来提高反应多样性的良好实践(Chen等人,2017),也是上述注意状态的实现解决方案(Grosz和Sidner,1986)。
在Reddit会话集上使用常识知识图ConceptNet进行的实验证明了ConceptFlow的有效性。在自动和人工评估中,ConceptFlow显著优于各种基于seq2seq的生成模型(Sutskever et al.,2014),以及以前的方法,这些方法也利用常识知识图,但是只是作为静态记忆(Zhou et al.,2018a;Ghazvinejad et al.,2018;Zhu et al.,2017)。值得注意的是,ConceptFlow的性能也优于两个经过微调的GPT-2系统(Radford等人,2019年),同时使用的参数减少了70%。显式建模会话结构提供了更好的参数效率。
3. Methodology
3.1 Preliminary
用户语句:\(X=\{x_1,...,x_m\}\),共\(m\)个单词 会话生成模型通过encoder-decoder生成响应:\(Y=\{y_1,...,y_n\}\)
编码器将用户语句\(X\)表示为表示集\(H={\vec h_1,...,\vec h_m}\),这一步由GRU得到:\(\vec h_i=GRU(\vec h_{i-1},\vec x_i)\),\(\vec x_i\)是\(x_i\)的embedding。
解码器根据先前\(t-1\)个单词生成的\(y_{<t}=\{y_1,...,y_{t_1}\}\)和用户话语\(X\)生成相应的第\(t\)个单词\(y_t\):
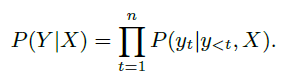
然后最小化交叉熵损失函数L,并端到端优化所有参数: \[ L=\sum_{t=1}^nCrossEntropy(y_t^*,y_t) \] 其中\(y_t^*\) is the token from the golden response.
ConceptFlow的体系结构图如下:
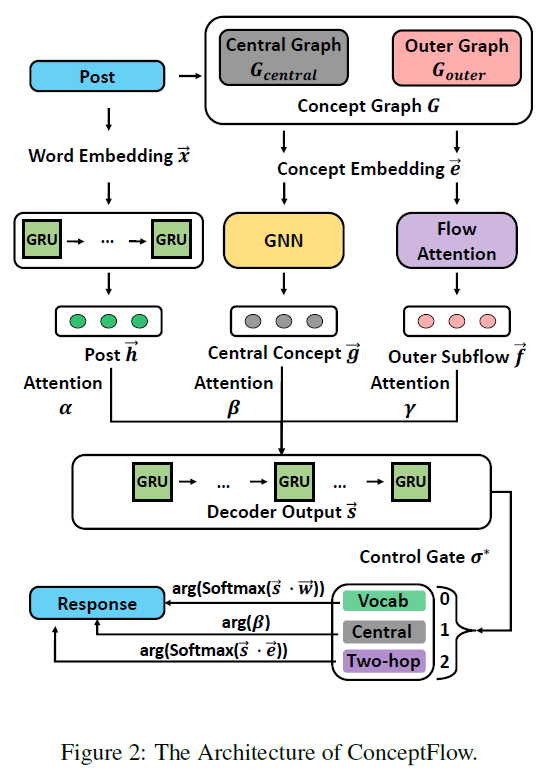
ConceptFlow首先根据与固定概念之间的距离(跳数)构造一个概念图\(G\),其中中心图为\(G_{central}\),外部图为\(G_{outer}\)【Sec. 3.2】
然后利用图神经网络和概念嵌入(concept embedding)技术将中心概念流和外部概念流分别编码到中心图和外部图中。【Sec. 3.3】
【Sec. 3.4】中介绍的解码器利用概念流和对话编码来生成用于响应的单词或概念。
3.2 Concept Graph Construction
- ConceptFlow构造一个概念图G来作为每个会话的知识。它从出现在会话语句中并有实体链接系统标注的根概念(grounded concepts)(零跳概念\(V^0\))开始。
- 然后ConceptFlow用一跳概念(\(V^1\))和二跳概念(\(V^2\))来增长零跳概念(\(V^0\))。来自\(V^0\)和\(V^1\)的概念以及它们之间的所有关系构成了中心概念图\(G_{central}\),它与当前会话主题密切相关,\(V^1\)和\(V^2\)中的概念及其联系构成了外图\(G_{outer}\)。
3.3 Encoding Latent Concept Flow
- 构造的概念图提供了关于概念如何与常识知识相关的显式语义。ConceptFlow利用它对会话进行建模并知道响应的生成。它从用户的话语开始,经过中心图\(G_{center}\),到外部图\(G_{outer}\),这是通过根据用户的话语对中心和外部概念流进行编码来建模的。
3.3.1 Central Flow Encoding
- 中心概念图\(G_{center}\)由一个图神经网络编码,该网络将信息从用户话语\(H\)传播到中心概念图。具体来说,它将概念\(e_i \in G_{central}\)编码表示为: \[ \vec g_{e_i}=GNN(\vec e_i,G_{central},H) \] 其中\(\vec e_i\)是\(e_i\)的concept embedding。具体使用哪种GNN网络没有限制,本文选择了Sun等人(2018)的GNN(GraftNet),它在编码知识图方面表现出很强的有效性。
3.3.2 Outer Flow Encoding
从\(e_p \in V_1\)跳到与其相连的两跳概念\(e_k\)的外部流动\(f_{e_p}\)通过注意力机制编码到\(\vec f_{e_p}\): \[ \vec {f_{e_p}}=\sum_{e_k} \theta ^{e_k} \cdot [\vec e_p \circ \vec e_k] \] 其中 \(\vec e_p\)和\(\vec e_k\) 是 \(e_p\)和\(e_k\) 的embedding;concatenated(\(\circ\));
注意力\(\theta^{e_k}\)聚合了概念三元组\((e_p,r,e_k)\)以获得\(\vec {f_{e_p}}\): \[ \theta ^{e_k}=softmax((w_r\cdot \vec r)^T\cdot tanh(w_h \cdot \vec e_p+w_t \cdot \vec e_k)) \] 其中\(\vec r\)是概念\(e_p\)和它相邻概念\(e_k\)的关系embedding;\(w_r,w_h,w_t\)是需要训练的参数。它提供了一个有效的注意力,特别是对于多跳概念之间的关系。
3.4 Generating Text with ConceptFlow
- 为了同时考虑用户语句和相关信息,decoder使用两个组件合并来自用户语句和潜在概念流的文本
- 结合其编码器的上下文表示【Sec 3.4.1】
- 从上下文表示中有条件地生成单词和概念【Sec 3.4.2】
3.4.1 Context Representation
为了生成第t个时间的相应令牌,我们首先根据语句编码和潜在概念流计算第t个时间decoder输出的上下文表示\(\vec s_t\)。
准确说,\(\vec s_t\)是通过利用第\((t-1)\)步的上下文表示\(\vec c_{t-1}\)来更新第\((t-1)\)步的输出表示\(\vec s_{t-1}\)来计算的: \[ \vec s_t=GRU(\vec s_{t-1},[\vec c_{t-1}\circ \vec y_{t-1}]) \]
其中\(\vec y_{t-1}\)是第\(t-1\)步生成的token\(y_{t-1}\)的embedding;上下文表示\(\vec c_{t-1}\)concatenate了基于文本的表示\(\vec c_{t-1}^{text}\)和基于概念的表示\(\vec c_{t-1}^{concept}\): \[ \vec c_{t-1}=FFN([\vec c_{t-1}^{text}\circ \vec c_{t-1}^{cpt}]) \]
基于文本的表示(text-based representation) \(\vec c_{t-1}^{text}\)通过标准注意力机制读取用户语句编码\(H\)(Bahdanau et al., 2015): \[ \vec c_{t-1}^{text}=\sum_{i=1}^m \alpha_{t-1}^j \cdot \vec h_j \] 其中语句token的注意力\(\alpha_{t-1}^j\): \[ \alpha_{t-1}^j=softmax(\vec s_{t-1}\cdot \vec h_j) \]
基于概念的表示(concept-based representation)\(\vec c_{t-1}^{concept}\)是一个内部流动和外部流动的组合编码: \[ \vec c_{t-1}^{cpt}=(\sum_{e_i \in G_{center}}\beta_{t-1}^{e_i}\cdot\vec g_{e_i})\circ(\sum_{f_{e_p}\in G_{outer}}\gamma_{t-1}^f\cdot \vec f_{e_p}) \]
注意力\(\beta_{t-1}^{e_i}\)是在中心概念表示上的权重: \[ \beta_{t-1}^{e_i}=softmax(\vec s_{t-1} \cdot \vec g_{e_i}) \] 注意力\(\gamma_{t-1}^f\)在外部浮动概念上的权重: \[ \gamma_{t-1}^f=softmax(\vec s_{t-1} \cdot \vec f_{e_p}) \]
3.4.2 Generating Tokens
第\(t\)次的输出表示包括来自语句文本的信息、具有不同跳步的概念以及对它们的注意力。解码器利用\(\vec s_t\)生成第\(t\)个token以形成更多信息的响应。
先利用门(gate)\(\sigma^*\),通过选择单词(\(\sigma^*=0\))、中心概念(\(V^{0,1},\sigma^*=1\))和外部概念集(\(V^2,\sigma^*=2\))来控制生成 \[ \sigma^*=argmax_{\sigma \in\{0,1,2\}}(FFN_{\sigma}(\vec s_t)) \]
单词\(w\)、中心概念\(e_i\)和外部概念\(e_k\)的生成概率在词汇表和内部概念集\(V^{0,1}\)、外部概念集\(V^2\)上计算:
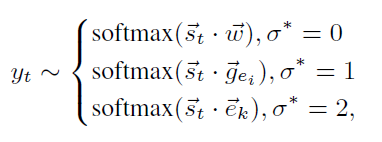
其中\(\vec w\)是词\(w\)的embedding,\(\vec g_{e_i}\)是概念\(e_i\)的在内部概念表示,\(\vec e_k\)是两跳概率\(e_k\)的embedding。
概念流的训练和预测遵循标准的条件语句模型,即使用公式15代替公式2,并通过交叉熵损失函数(公式3)进行训练。训练只使用真实响应,而不需要额外注释。