- 论文:https://arxiv.org/abs/1606.00979
1. 简介
- 深度学习提升向量建模方法的大体框架都很接近:根据问题确定主题词,根据主题词确定候选答案,通过候选答案和问题的分布式表达相似度得分确定最终答案。而方法的核心在于学习问题和候选答案的分布式表达,其实相关的方法都是在这两个部分做文章。这篇文章的想法在于,对于不同的答案,我们关注问题的焦点是不同的,我们根据候选答案的信息,来引入注意力机制,对同一个问题提取出不同的分布式表达。
- 比如 对于问题 "who is the president of France?",其中之一的答案是实体“Francois Holland”,我们通过知识库可以知道Francois Holland 是一个总统,因此我们会更加关注问句中的 “president” 和 “France” 单词,而根据Francois Holland的类型person,我们会更关注问句中的疑问词who。
2. 过程
2.1 将候选答案转化为分布式表达
- 我们从多个方面考虑答案的特征:答案实体、答案上下文环境(知识库中所有与答案实体直接相连的实体)、答案关系(答案与问题主题词之间的实体关系)、答案类型。每一种特征都可以用\(v_k\)维的multi-hot向量表示,\(v_k\)即知识库实体和实体关系的数量之和。我们通过Embedding矩阵\(E_k\)将每一种特征转化为低维的分布式表达,我们就得到了四种关于答案的分布式表达\(e_e,e_c,e_r,e_t\)(其中由于答案上下文环境涉及的实体较多,我们取这些实体的embedding均值作为上下文环境的embedding)。
2.2 将自然语言问题转化为分布式表达
- 将问句中的每一个单词经过Embedding矩阵\(E_w\)转化为wrod-embedding,使用双向LSTM(bi-LSTM)提取问句特征。bi-LSTM第\(j\)时刻的输出记作\(h_j\),使用bi-LSTM的好处在于\(h_j\)既包含了第\(j\)个单词之前的信息,又包含了该单词之后的信息。
2.3 在得分函数中引入注意力机制
我们希望我们问句的分布式表达对于四种不同的答案特征有不同的表达(根据答案特征对于问题有不同的关注点),第\(i\)种答案的分布式表达\(e_i\)对应的问句分布式表达记作\(q_i\),我们的得分函数定义为四种对应表达的点乘之和,即:
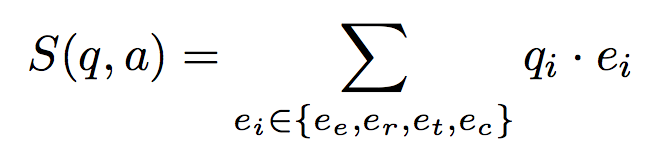
对于一般的LSTM,我们通常将最后一个时刻的输出\(h_T\)作为句子的最终表达,而在这里,我们引入注意力机制,根据问题的特征,给予每一时刻的输出不同程度的关注(对bi-LSTM每一时刻的输出进行加权求和),即:
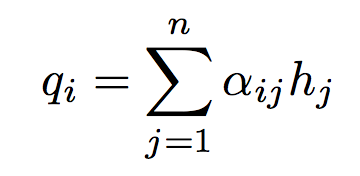
其中的权重系数\(a_{ij}\)取决于bi-LSTM第\(j\)时刻的输出\(h_j\)和第\(i\)种答案特征的分布式表达\(e_i\),因此可以使用一个单层的神经网络去学习这个权重,并通过Softmax对权重进行归一化,公式如下:
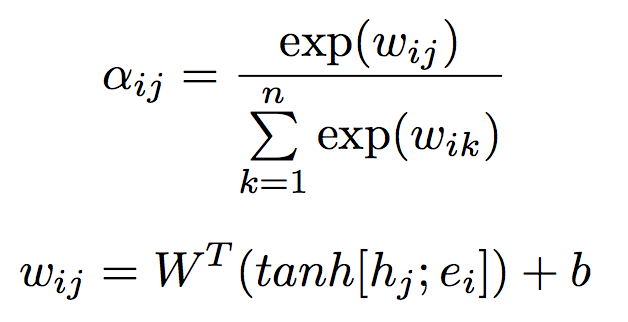
2.3 OOV问题
- 在测试过程中,我们的候选答案可能从未在训练集中出现过,因此它对应的分布式表达是没有被我们的模型训练过的(这个问题称为the problem of out of vocabulary, OOV)。为了解决该问题,作者利用TransE对知识库进行训练,训练实体和实体关系对应的Embedding矩阵\(E_k\)(实际操作中,作者通过轮流训练KB-QA模型和TranE的方式训练并共用Embedding矩阵\(E_k\),每训练一个epoch的KB-QA就训练100个epoch的TransE)。这样,我们就利用了整个知识库的特性,预先对每一个知识库实体都进行了训练,使得相似实体的分布式表达也很相似。因此,即使遇到KB-QA训练集中未遇到的候选答案实体,KB-QA模型也能将它视作是在训练集中出现过的某个和它分布式表达相似的实体,这样就减轻了OOV问题所带来的破坏性。
- 关于TransE:TransE是知识图谱补全的经典方法,它借鉴了word-embedding的思想,能够将知识库中的实体和实体关系用分布式向量表达。其主要思想是对于一个知识三元组(s,r,o),我们希望主语实体的分布式表达e(s)加上关系实体的分布式表达e(r)能够尽量接近宾语实体的分布式表达e(o),因此我们可以构建类似的margin-rank损失函数通过正样本和采样负样本进行训练。TransE提出之后还出现了大量的改进算法,诸如TransH、TransR、TransG、TranSparse、TransD等等。
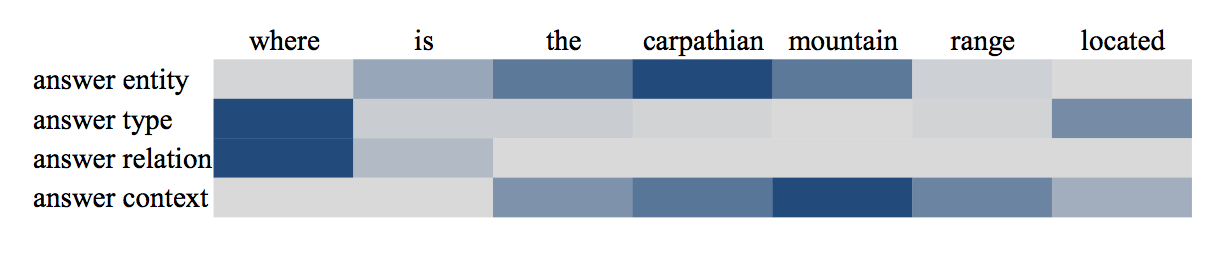
3. 实验环节
- 注意力机制的好处:可视化,通过可视化每个单词的权重,可以得到一些可解释性,如下图: