- 论文:https://arxiv.org/abs/1506.02075
1. 简介
当时的KB-QA对于解决只依赖一个知识三元组的简单问题(称为Simple Question Answering)仍有些困难,为此作者构建了一个更大的简单问题数据集,称作SimpleQuestions。该数据集的每个问题都依据一个知识三元组知识,进行人工构建问题,数据集最终一共包含了108,442个问题-答案对,相比之前只含8000多个问题-答案对的benchmark数据集WebQuestion,其数据量大了很多。该数据集的部分数据如下图所示(下划线表示答案):

整体思想是将知识库里的知识存储到记忆模块M中,问题经过输入模块I转化为分布式表达,输出模块O选择与问题最相关的支撑记忆(由于SimpleQuestions的问题只依赖一个知识,所以只需要选择一条记忆),回答模块R将该记忆对应三元组的宾语作为最终答案输出。
在模型训练完毕后,我们将Reverb中提取的三元组(Reverb的知识三元组是自然语言形式,如(“Obama”, “was also born in”, “August 1961”),知识三元组抽取自ClueWeb)作为新的知识,用泛化模块G将新知识存储到记忆模块中,在不经过re-training的情况下使用该记忆回答问题,测试模型的泛化性能。
2. 整体流程
2.1 存储知识
- 首先将知识库中的知识存储到记忆网络中。作者使用Freebase的两个子集FB2M(含2M实体和5K实体关系)和FB5M(含5M实体和7K实体关系)分别作为知识库。使用输入模块I来处理数据。
- 由于一个问句可能有多个答案,并且对于一个问题输出模块O只能选择一个支撑记忆,我们先对知识做两种预处理:
- 将具有相同主语和实体关系的三元组进行合并(Group),这样每一条知识将包含k个不同的宾语,即\(y=(s,r,\{o_1,...,o_k\})\)。合并的原因在于我们想用一条记忆回答具有多个答案的问题(我们将合并前的知识三元体成为Atomic Facts,合并后的三元组成为Facts),合并后和合并前的知识库大小如下:
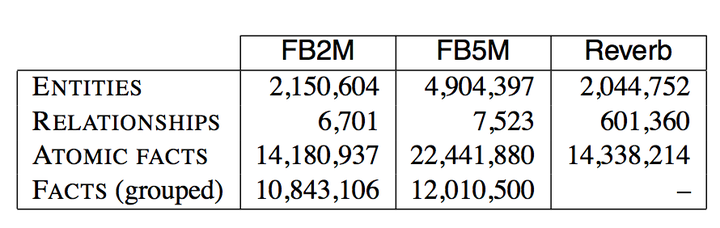
- 去除中间节点。有些知识中日期会链接两个实体以区分某一事实的时间范围,我们可以将中间节点(mediator node)去除转化成一个二阶关系,这样我们就把长度为2的路径压缩成了长度为1的路径,即压缩为一个三元组。这个操作使得WebQuestion里的能被单一关系回答的问题数量从65%上升到86%。
- 将具有相同主语和实体关系的三元组进行合并(Group),这样每一条知识将包含k个不同的宾语,即\(y=(s,r,\{o_1,...,o_k\})\)。合并的原因在于我们想用一条记忆回答具有多个答案的问题(我们将合并前的知识三元体成为Atomic Facts,合并后的三元组成为Facts),合并后和合并前的知识库大小如下:
- 预处理完知识后,我们的输入模块I对知识进行预处理并存储到记忆中。这里使用词袋模型bag-of-symbol的方法,用一个\(N_S\)维的multi-hot向量\(f(y)\)来表示每一条知识并作为记忆。\(N_S\)的大小为知识库实体和实体关系的大小之和,主语实体\(s\)和实体关系\(r\)对应向量维的值为1,宾语实体\(o_i\)对应维的值设为\(1/k\)。
2.2 训练记忆网络
- 使用问题-答案对来训练记忆网络。
- 首先用输入模块I来处理输入的自然语言问句\(q\),我们使用n-gram词袋模型(bag-of-ngrams)方法,用一个\(N_V\)维的multi-hot向量\(g(q)\)来表示每一个问句。\(N_V\)的大小是字典大小,字典包含所有问题中出现的单词和所有知识库实体的自然语言别称(这个别称可能由多个单词构成,我们用1个n-gram来表示)。
- 对于输入\(g(q)\),我们的输出模块O要在记忆中寻找一个与之最相关的支撑记忆。为了避免遍历整个记忆模块里的每一条知识,我们先确定一个候选范围。确定方式如下,将问句中的所有n-gram与知识库实体别称进行匹配,以确定候选实体,将含有候选实体作为主语的知识作为我们的候选支撑记忆。我们将记忆和问题投影到一个低维分布式空间,通过consine相似度作为得分函数,来寻找最相关的支撑记忆,即:\(S_{QA}(q,y)=cos(W_Vg(q),W_Sf(y))\)。这里我们需要学习的参数就是两个权值矩阵\(W_V,W_S\)。
- 这里与[[4. Multi-Column向量建模-Question Answering over Freebase with Multi-Column Convolutional Neural Networks]]提到的训练方法一样,我们构建margin-based ranking损失函数,也进行多任务的训练,通过多任务训练让语义相同的问题的分布式表达\(W_V(q)\)相似。
- 需要注意的是,我们知道构建margin-based ranking损失函数需要提供支撑记忆的正样本和负样本,由于SimpleQuestion数据集的每个问题都有对应的知识标签,因此我们已经有支撑记忆的正确标签。但是对于WebQuestion数据集,我们没有正确的支撑记忆标签,作者通过类似之前寻找候选支撑记忆的方式去得到标签。
2.3 测试网络泛化能力
- 使用泛化模块G来连接新的知识库Reverb到我们的记忆中,通过实体链接和实体别名匹配等方式,来匹配已有记忆中的实体和新知识库里的实体(这种方式只能匹配到新知识库中17%的实体)。新知识库中剩下的实体和所有的关系都用词袋模型表示,因此我们可以用一个\(N_V+N_S\)维的向量来\(h(y)\)表示新知识并将其存储到记忆中。同样的,输出模块在寻找支撑记忆时的相似度得分函数为\(S_{RVB}(q,y)=cos(W_Vg(q),W_{VS}h(y))\),其中矩阵\(W_{VS}\)直接由之前训练好的\(W_V,W_s\)拼接(concatenate)而成。