- 论文原文:http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.650.469&rep=rep1&type=pdf
1. 简介
- 本论文中的方法通过提取问题中的实体,通过在知识库中查询该实体可以得到以该实体节点为中心的知识库子图,子图中的每一个节点或边都可以作为候选答案。通过观察问题,依据某些规则或模版进行信息抽取,得到表征问题和候选答案特征的特征向量,建立分类器,通过输入特征向量对候选答案进行筛选,从而得出最终答案。
- 导入
- 如何回答问题?
- 问题: “what is the name of Justin Bieber brother?”
- 主题词(topic)是Justin Bieber,因此我们会去知识库中搜索Justin Bieber这个实体,寻找与该实体相关的知识(此时相当于我们确定了答案的范围,得到了一些候选答案)。接下来我们去寻找和实体关系 brother相关的实体(事实上freebase里没有brother这个实体关系,而是sibling,我们需要进行一个简单的推理),最后得到答案。)
- 如何确定候选答案
- 根据主题词,结合知识库,确定候选答案。如果我们把知识库中的实体看作是图节点,把实体关系看作是边,那么知识库就是一个庞大的图,通过主题词对应图节点的相邻几跳(hop)范围内的节点和边抽取出来得到一个知识库的子图,这个子图本文称为主题图(Topic graph),一般来说,这里的跳数一般为一跳或两跳,即与主题词对应的图节点在一条或两条边之内的距离。主题图中的节点,即是候选答案。接下来,需要继续观察问题,对问题进行信息抽取,获取能帮助我们在候选答案中筛选出正确答案的信息。
- 如何对问题进行信息抽取
- 结合人的理解,先对句子结构进行分析,下图是"what is the name of Justin Bieber brother"语句的语法依存树(Dependency tree)。
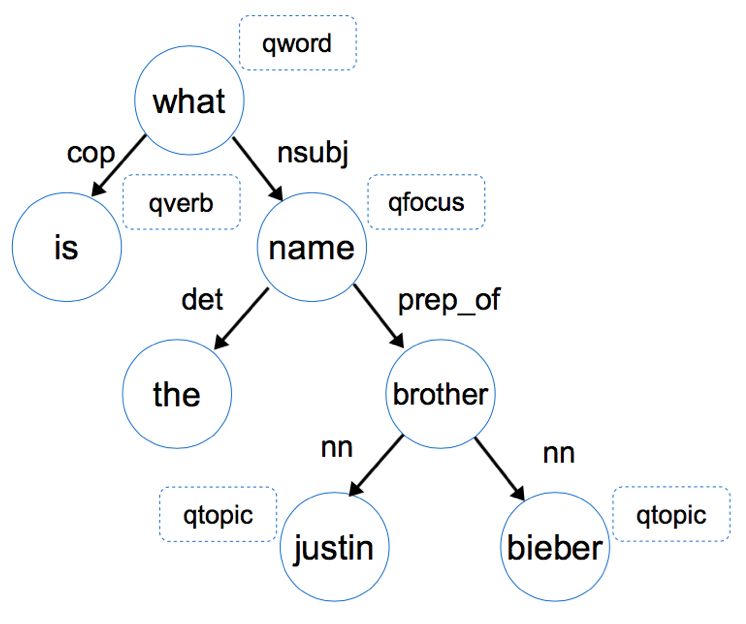
- 首先通过依存关系nsubj(what,name)和prep_of(name, brother)这两条信息知道答案是一个名字,并且这个名字和brother有关,当然我们此时还不能判断是否是人名。进一步,通过nn(brother, Justin Bieber)这条信息我们可以根据Justin Bieber 是个人,推导出他的brother也是个人,综合前面的信息,可以推理出我们最终的答案应该是个人命。(注:nsubj代表名词性主语,prep_of代表of介词修饰,nn 代表名词组合),当确定了最终答案是个人名,就很容易在候选答案中筛选出正确答案了。
- 本质上是对问题进行信息抽取
2. 论文中的处理
3.1 信息抽取
- 首先提取的第一个信息就是问题词(question word, 记作qword),例如 who, when, what, where, how, which, why, whom, whose,它是问题的一个明显特征 。
- 第二个关键信息,就是问题焦点(question focus, 记作qfocus)这个词暗示了答案的类型,比如name/time/place,我们直接将问题词qword相关的那个名词抽取出来作为qfocus,在这个例子中,what name中的name就是qfocus
- 第三个需要的信息,就是这个问题的主题词(word topic,记作qtopic),在这个句子里Justin Bieber就是qtopic,这个词能够帮助我们找到freebase中相关的知识,我们可以通过命名实体识别(Named Entity Recognition,NER)来确定主题词,需要注意的是,一个问题中可能存在多个主题词。
- 最后需要提取的特征是问题的中心动词(question verb,记作qverb),词能够给我们提供很多和答案相关的信息,比如play,那么答案有可能是某种球类或者乐器。我们可以通过词性标注(Part-of-Speech,POS)确定qverb。
- 总结:通过对问题提取 问题词qword,问题焦点qfocus,问题主题词qtopic和问题中心动词qverb这四个问题特征,我们可以将该问题的依存树转化为问题图(Question Graph),如下图所示
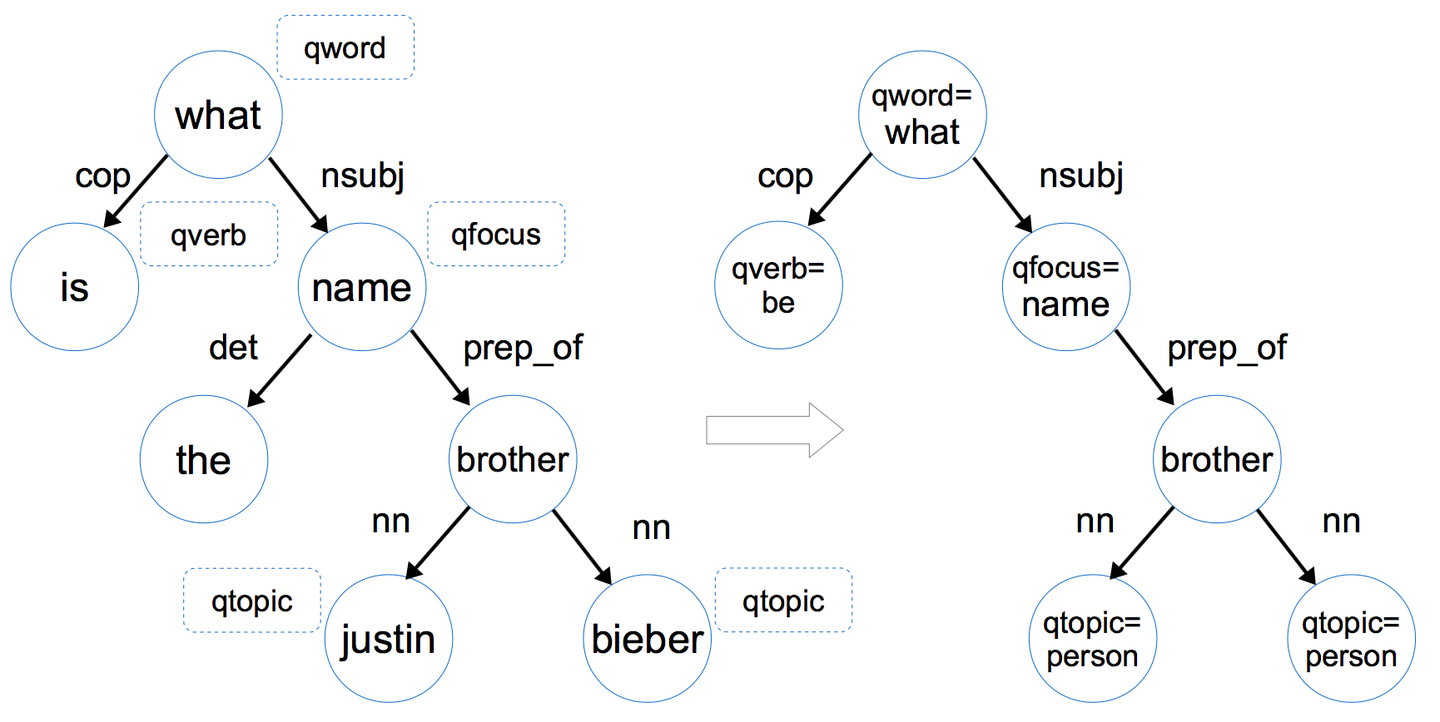
- 总结来说,将依存树转化为问题图进行了三个操作:
- 将问题词qword,问题焦点qfocus,问题主题词qtopic和问题中心动词qverb加入相对应的节点中,如what -> qword=what。
- 如果该节点是命名实体,那就把该节点变为命名实体形式,如justin -> qtopic=person (justin对应的命名实体形式是person)。这一步的目的是因为数据中涉及到的命名实体名字太多了,这里我们只需要区分它是人名 地名 还是其他类型的名字即可。
- 删除掉一些不重要的叶子节点,如限定词(determiner,如a/the/some/this/each等),介词(preposition)和标点符号(punctuation)。
- 从依存树到问题图的转换,实质上就是对问题进行信息抽取,提取出有利于寻找答案的问题特征,删减掉不重要的信息
3.2 构建特征向量对候选答案进行分类
- 在候选答案中找出正确答案,实际上是一个二分类问题(判断每个候选答案是否是正确答案),我们使用训练数据问题-答案对,训练一个分类器来找到正确答案。分类器的输入特征向量中的每一维,对应一个问题-候选答案特征。每一个问题-候选答案特征由问题特征中的一个特征,和候选答案特征的一个特征,组合(combine)而成。
- 问题特征:我们从问题图中的每一条边e(s,t),抽取4种问题特征:s,t,s|t,和s|e|t。如对于边prep_of(qfocus=name,brother),我们可以抽取这样四个特征:qfocus=name,brother,qfocus=name|brother 和 qfoc us=name|prep_of|brother。
- 候选答案特征:对于主题图中的每一个节点,我们都可以抽取出以下特征:该节点的所有关系(relation,记作rel),和该节点的所有属性(property,如type/gender/age)。对于Justin Bieber 这个topic我们可以在知识库找到它对应的主题图,如下图所示:

- (注:图中虚线表示属性,实线表示关系,虚线框即属性值,实现框为topic node。在知识库中,如果同一个topic节点的同一个关系对应了多个实体,如Justin Bieber的preon.sibing_s关系可能对应多个实体,那freebase中会设置一个虚拟的dummy node,来连接所有相关的实体)
- 例如,对于Jaxon Bieber这个topic节点,我们可以提取出这些特征:gender=male,type=person,rel=sibling 。可以看出关系和属性都刻画了这个候选答案的特征,对判断它是否是正确答案有很大的帮助。
- 问题-候选答案特征:每一个问题-候选答案特征由问题特征中的一个特征和候选答案特征中的一个特征,组合(combine)而成(组合记作 | )。我们希望一个关联度较高的问题-候选答案特征有较高的权重,比如对于问题-候选答案特征 qfocus=money|node type=currency(注意,这里qfocus=money是来自问题的特征,而node type=currency则是来自候选答案的特征),我们希望它的权重较高,而对于问题-候选答案特征qfocus=money|node type=person我们希望它的权重较低。
-------------本文结束 感谢阅读-------------