Attention Is All You Need
Abstract
之前好的序列模型是基于复杂的RNN或者CNN神经网络、拥有编码器和解码器的Seq2Seq模型,表现更佳的模型还可通过注意力机制来连接编码器和解码器。本文提出的新的网络架构,即Transformer,完全基于注意力机制而消除了RNN或CNN。并且效果更好。
1. Introduction
RNN,特别是LSTM及GRU,是目前序列分析的最新方法,之后就一直致力于扩大RNN和Seq2Seq体系结构的界限。
RNN是通过输入和输出序列的位置顺序来考虑计算,即将位置与时间步对齐,下个隐藏状态\(h_t\)是上一层隐藏状态\(h_{t-1}\)和这一层输入的函数。这种固有的顺序性质阻止了并行训练,尤其在较长序列上影响最为显著。最近的工作是通过分解技巧和条件计算使得在计算效率上取得了显著提高,同时后者还提高了模型性能。但是顺序计算的基本约束依然存在。
注意力机制变成序列模型不可或缺的一部分,综合考虑了整体依赖,而无需专注与在输入和输出序列中的距离,但注意力机制目前都是与RNN结合使用的。
本文提出了Transformer,它是完全依赖于注意力机制来描述输入和输出序列之间的全局依赖关系。并且效果很好。
2. Background
【凡是可以并行计算的,学习上下文依赖关系不行】
减少顺序计算的目标也推动了扩展神经网络GPU、ByteNet、ConvS2S的发展。这些都是用CNN作为基本构件,并行计算所有输入输出位置上的隐藏层。在这些模型中,关联前后文所需要的计算量在ConvS2S中是随距离增加线性增长的,而对于ByteNet则是随距离增加呈对数增长,从而难以学习到上下文之间的依赖关系。在Transformer中,这种操作可以被减少为恒定的操作次数,尽管是以平均注意力加权位置而导致的有效分辨率降低,但本文用3.2节中所述的Multi-Head Attention抵消了这种影响
Self-Attention是一种与单个序列不同位置相关的注意力机制,目的是计算序列的representation。Self-Attention也被广泛应用
End-to-end记忆网络是基于递归注意力的,而不是RNN[????],并且已经被证明在简单语言问答和语言建模任务中表现良好。
Transformer是第一个完全依赖self-attention的,而无需RNN或者CNN。
3. Model Architecture
encoder将输入序列\((x_1,...,x_n)\)映射到连续表示形式\(z=(z_1,...z_n)\)。给出\(z\),decoder一次性生成输出序列\((y_1,...y_m)\),每一步都是自回归的,生成下一个的时候都会把之前生成序列当成附加输入进行计算。
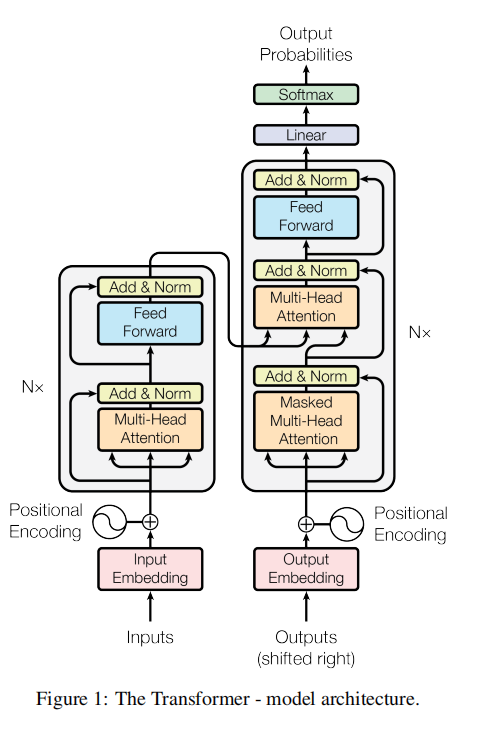
3.1 Encoder and Decoder Stacks
Encoder:由6个Block堆叠而成。每一层有两个子层:multi-head self-attention层和全连接层。两个子层都采用残差连接的形式,然后进行层归一化。即每一层的输出为\(LayerNorm(x+Sublayer(x))\),其中\(Sublayer(x)\)是由当前子层本身实现的功能。为了实现残差连接,模型中所有子层及嵌入层的输出均为512维。
Decoder:由6个Block堆叠而成。每层除了同Encoder层的两个子层外,还有针对encoder输出的multi-head attention的子层。每个子层也进行残差连接,然后进行层归一化。同时修改了self-attention子层来prevent positions from attending to subsequent positions。这种mask,加上output embeddings偏移一个位置,保证了位置i只能依赖于位置小于i的输出。
3.2 Attention
Attention为Query和一系列Key-Value对的映射输出。其中Q、K、V都是向量。
Attention的本质:The output is computed as a weighted sum of the Values, where the weight assigned to each value is computed by a compatibility function of the Query with the corresponding Key
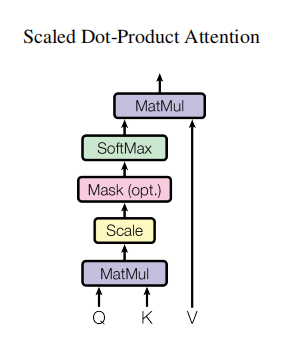
3.2.1 Scaled Dot-Product Attention
Input: \(Q(dim=d_k)\)、\(K(dim=d_k)\)、\(V(dim=d_v)\)
compute the dot products of the Query with all Keys, divide each by \(\sqrt {d_k}\)
and apply a softmax function to obtain the weights on the values.
the matrix of outputs: \[ Attention(Q,K,V)=softmax(\frac {QK^T}{\sqrt {d_k}})V \]
two commonly used attention functions: additive attention; dot-product attention
- dot-product与我们算法相同,只是有个比例因子\(\sqrt {d_k}\)
- additive attention是利用一个具有单个隐藏层的前馈网络来计算compatibility的。
- 二者理论上复杂度相似,但前者可以使用高度优化的矩阵乘法实现,故速度更快,空间效率更高。
对于\(d_k\)值较小的情况,以上两种机制表现相似。但对于较大值的\(d_k\),后者优于前者,可能是对于较大的\(d_k\),dot-products在数量级上增长很大,从而将\(softmax\)函数推倒梯度非常小的区域。故为抵消这种影响,采用\(\frac {1}{\sqrt {d_k}}\)缩放。
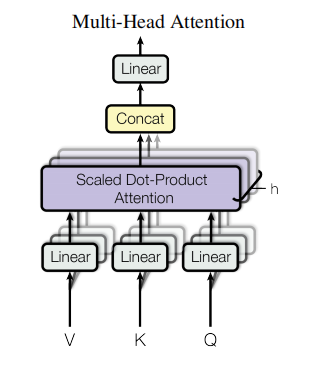
3.2.2 Multi-Head Attention
并行执行多个Attention Function【多头 multi-head】将Q、K、V投影到不同\(d_v\)维的输出值上,将其concatenate在一起再进行线性投影,得到最终值
the matrix of outputs: \[ MultiHead(Q,K,V)=Concat(head_1,...head_h)W^O\\ \qquad\qquad where\ head_i=Attention(QW_i^Q,KW_i^K,VW_i^V) \] the dimension of each parameter matrices: \[ W_i^Q:d_{model}×d_k\\ W_i^K:d_{model}×d_k\\ W_i^Q:d_{model}×d_v\\ W^O:hd_v×d_{model} \] 在这项工作中,采用\(h=8\)个平行的Attention Layers。由于输出维数【\(d_{model}\)】固定为512【本文中假设的】,故\(d_k=d_v=d_{model}/h=64\)。由于每个头部的维数减小,总的计算量与单头Attention计算量类似。
Multi-head attention可以使得模型能够在不同的位置共同关注来自不同子空间的信息。
3.2.3 Applications of Attention in our Model
- Transformer使用multi-head attention主要有三点不同:
- 在"encoder-decoder attention"层中,Query是来自前一层decoder层,Key和Value是来自encoder的输出。这使得decoder中每个位置都可以参考到输入序列中的所有位置。这种模仿了典型的encoder-decoder网络。
- encoder包含self-attention层。在self-attention层中,所有的K、V、Q都来自同一个地方,在本例中是encoder中前一层的输出。encoder中的每个位置都可以关注encoder前一层中的所有位置信息。
- 同样的,decoder中的self-attention层允许decoder中的每个位置关注到decoder中包含本位置在内的所有位置信息。为了防止decoder中的信息往左流动,已保证auto-regressive特性。通过[???????????]
3.3 Position-wise Feed-Forward Networks
- 除了attention子层外,encoder和decoder中的每一层都包含一个全连接的前馈网络,这个网络分别应用在每个位置,参数是一样的。包含两个线性变换,激活函数为ReLU【就是max那一部分】
\[ FFN(x)=max(0,xW_1+b_1)W_2+b_2 \]
3.4 Embeddings and Softmax
- 我们先使用embeddings把input和output转换为\(d_{model}\)维的向量。我们也使用通常的线性变换和\(softmax\)函数来将解码器的输出转换为下一个词的概率。
- 不同词计算K、Q、V时共享\(W_K,W_Q,W_V\)矩阵,同时在embedding层再把这些权重乘\(\sqrt {d_{model}}\)
3.5 Positional Encoding
由于我们的网络不包含递归和卷积,为了使模型利用序列的顺序特性,我们必须注入一些关于序列的相对或绝对位置信息。
The positional encodings have the same dimension \(d_{model}\) as the embeddings, so that the two can be summed。有很多位置编码可以选择,learned和fixed
公式: \[ PE_{(pos,2i)}=sin(pos/10000^{2i/d_{model}})\\ PE_{(pos,2i+1)}=cos(pos/10000^{2i/d_{model}}) \] 位置编码的每个维度对应与一个正弦曲线。波长呈几何级数从\(2π\)到\(10000·2π\)。之所以选择这个函数是因为它可以让模型很容易的通过相对位置来学习,因为对于任意固定的偏移量\(k\),\(PE_{pos+k}\)可以表示为\(PE_{pos}\)的线性函数