莫烦-NLP快速入门
1. 搜索
1.1 TF-IDF算法
正排/倒排索引
正排索引是在每次搜索时都对所有材料进行阅读,然后找出关键词,效率差
倒排索引是第一次拿到材料时即构造索引,后续搜索中复用,即一种词语匹配加返回索引材料的过程。
TF-IDF算法(处理匹配排序)
位于提高精确度,对筛选出来的内容做一个【问题与内容】的相似度排序。
TF(Term Frequency):词频 IDF(Inverse Document Frequency):逆文本频率指数

TF是以文章为中心的局部词信息;IDF是全局的词信息的区分力大小,越大则区分力越高;结合即可通过TF-IDF信息来表达文章了
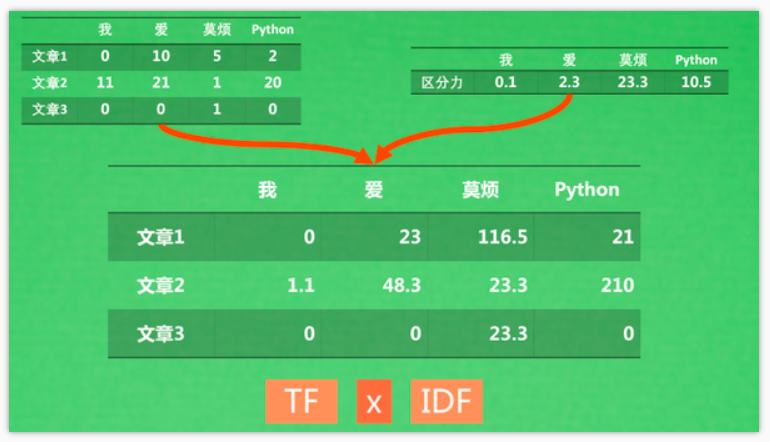
搜索时会计算搜索问句的TF-IDF的值,将问句和文章转变成向量(上例中为四维)投射到空间中,然后计算问句和每篇文章的cosine距离(角度距离)。
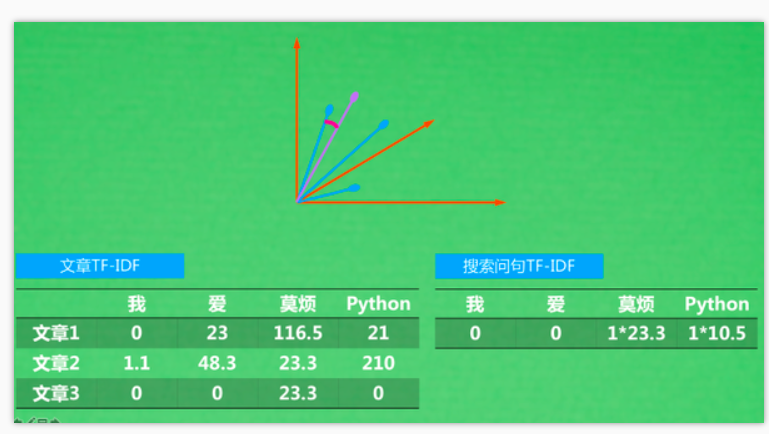
可作为取关键词的依据,但某个领域的IDF表可能相似度很高,所以可以用一个带有金融属性的IDF表来优化对金融子领域的搜索。IDF虽然带有全局信息,但只是一个领域,一个子集。
集群版搜索引擎 ElasticSearch:框架,可处理海量数据,用到BM25算法
有Python+Numpy和sklearn两种实现代码
2. 理解词语
2.1 词向量
相似度可凭角度信息及距离信息判断
CBOW(Continuous Bag of Words)
挑一个要预测的词,来学习这个词前后文中词语和预测词的关系。
3. Seq2Seq
TF-IDF等是表达文章采用的是词频的信息,但忽略了顺序。
RNN可获取到顺序的信息
3.2.1Encode
变成计算机理解的向量表达形式,可使用RNN等,压缩器
3.2.2 Decoder
翻译成各种不同的表示形式,解压器
训练(training)中,不管有没有预测错,下一步在decoder的输入都是正确的
预测(inference)中,decoder下一步的预测基于decoder上一步预测,而不是true label
3.3 Attention机制
模型注意局部的文字信息
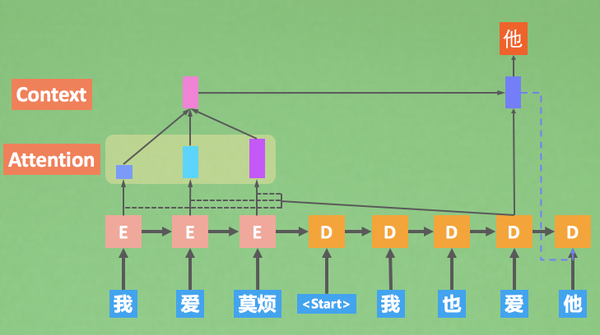
生成 爱 时,将前面整体的信息进行softmax,也就是打权重,即了解应加强注意到哪些encoder的step上面,再生成一个加了注意力后的全局信息,在结合上decoder现在的信息一起生成字。即$ LuongAttention \(方法。\) [Effective Approaches to Attention-based Neural Machine Translation] $
论文中提出了三种计算attention score的方式
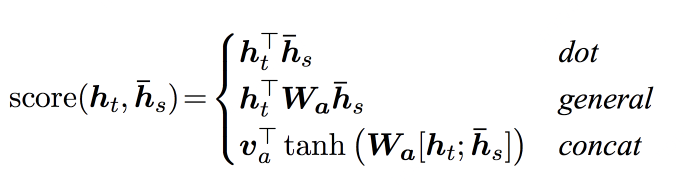
$ h_t \(是decoder见到输入生成的hidden state,\) h_s $是encoder见到的输入时生成的hidden state。意思是将decoder每预测一个词,都拿这个decoder现在的信息去和encoder所有信息做注意力的计算,即可得到如何将注意力放到encode当中。三个公式的不同点就是是否要引入更多的学习参数和变量
以此为Seq2Seq(RNN+Attention)模型,采用RNN进行encoder,decoder
模型经过多次注意,不同层级的注意力带来的是不同层级上的理解。越是后面的注意,就是越深度的思考。也就是Transformer模型。
4. Transformer模型
一个个注意力矩阵来表示在不同位置的注意力强度。通过控制强度来控制信息通道的阀门大小。也可多个人同时观察一句话,然后汇总每个人通过自己的注意力得到的结论,再进入下一轮注意力
RNN中采用时序模型的encoder,把整句话encoder进来,再通过一个一个词去看根据局部信息判断一个个词需要施加多少注意力。
Transformer可以直接一层层叠加注意力,RNN也可以又叠加模式,但是太慢了,Transformer可以采用CNN的那种模式进行加速,而RNN必须先看第一步再第二步,必须时序进行,太慢了。Transformer基于每一层的理解,计算机视觉也是通过不断卷积,得到每一层的理解,卷积也可以当成过滤器。采用transformer或attention进行encode
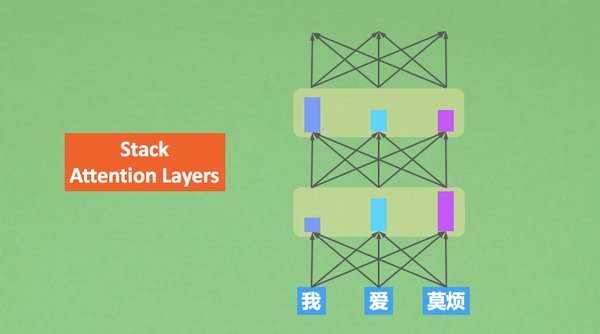
encode
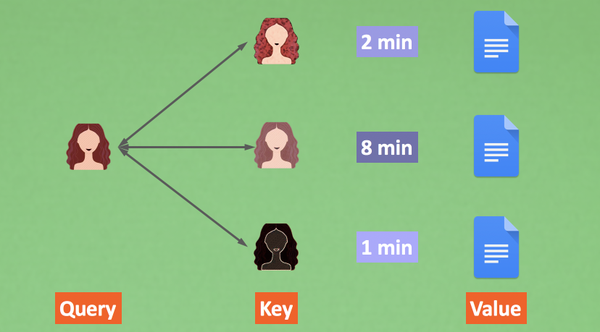
上图:Query和所有候选人Key做对比,得到一个要注意的程度Attention,根据这个程度判断需要花多久时间仔细阅读候选人材料Value
同时施加多个Attention hat,好几个人帮我一轮轮注意+理解后,我再汇总所有人的理解,统一判断
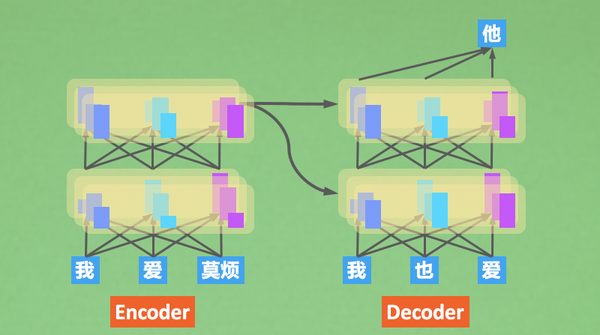
decode
Encoder里的注意力叫做自注意力(self-attention)
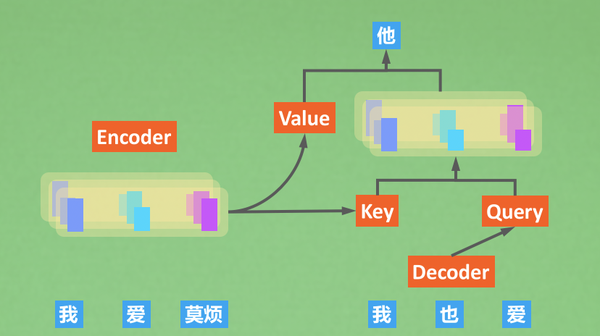
在Decoding时,decoder会向encoder借一下Key和Value,Decoder自己可以提供Query(已经预测出来的token)。使用我们刚刚提到的K,Q,V结合方式计算。 不过这张图里面还有些细节没有提到,比如 Decoder 先要经过Masked attention再和encoder的K,V结合,然后还有有一个feed forward计算,还要计算残差。
- Masked attention: 不让decoder在训练的时候用后文的信息生成前文的信息;
- Feed forward: 这个encoder,decoder都有,做一下非线性处理;
- 残差计算:这个也是encoder和decoder都有,为了更有效的backpropagation。
5. 预训练模型
我们需要进行一次知识的通用编码,将它转化成文字,动画,声音等等,下一代人还能通过学习获取统一解码能力,将编码的文字,动画,声音解码转移至自己的大脑中,完成知识的迁移。机器可以复制,即可以完成“学习型遗传信息”的传递。
大规模深度学习模型就像一个知识体,可以用多种不同的模型框架来存储知识,比如双向LSTM模型、Transformer模型等,特点是大、参数多。我们再次利用这些存储知识时,需要将固化下来的神经连接稍作修改,来适应变化,这种超大规模的模型柔韧性好,相比小模型又大量的神经连接相互牵连,不会很容易随着一点变化而完全跑偏,这也是大模型比小模型更好做知识迁移的原因之一。
如果模型变大变深,效果提升会更显著。每训练一个大模型,都要消耗很长时间,我们并不希望浪费太多时间在训练上,所以拿到一个预训练模型是十分重要的。基于预训练模型,我们能够用较少的模型较快的得到一个适合我们自己数据的新模型,而且效果也不会差。预训练的核心价值是:
- 手头只有小数据集,也能得到一个好模型
- 训练速度大大提升,不用从零开始
5.1 ELMo(Embeddings from Language Model)模型
- 主要目标:找出词语放在句子中的意思。CBOW或者skip gram没有办法表示词在句子中的不同含义,故ELMo可一词多义
- 通过双向RNN(LSTM)架构来使词向量拥有上下文信息,每个词的向量表达,可看做下面信息的累积:
- 从前往后的前文信息
- 从后往前的后文信息
- 当前词语的词向量信息
- ELMo是预训练模型的先驱,也认真对待了一词多义的情况。但是预训练模型并不仅仅局限于ELMo这种RNN模式的框架,Transformer同样可以做预训练,并且效果更好,比如GPT, Bert
5.2 GPT(Generative Pre-Training)单向语言模型
- 预训练需要很多算力资源,单向的代表只能从前往后,但是拟合能力依旧很好
- 用着Decoder的Future Mask(Look Ahead Mask),但结构更像Encoder搞一个双向链接
- 用前文的信息预测后文的信息,所以用上了Future Mask,不然要做大量预料的非监督学习,会让模型在预测A时看到A的信息,从而有一种信息穿越的问题。因为Transformer这种MultiHead Attention模式,每一个Head都会看到所有的文字内容,如果用前文的信息预测后文内容又不用Future Mask时,模型是可以看到要预测信息的,这种训练是无效的
- Decoder少了一些连接Encoder的层
- 只使用了Future Mask做注意力
5.3 BERT双向语言模型
- 在句子里遮住X,不让模型看到X,然后用前后文信息预测X
- 把词替换成mask,但是机器不能识别意思,mask会被当成一个词去理解,会以为我要用“mask”这个词向量预测什么,所以具体替换方式为:随机选取15%的词做如下改变
- 80%的时间,将它替换成[MASK]
- 10%的时间,将它替换成其他任意词(错别字)
- 10%的时间,不变
- 除了预测,也可以判断两句话是不是上下文关系